It’s not unusual to stumble upon ambiguous link phrases on web pages (phrases such as, “Click here”, “More”, and so on). Some screen readers allow users to gather a list of links from a page, but these types of link phrases are usually meaningless when read out of context. This article demonstrates a technique that allows ambiguous link phrases to be rendered visually in a page, whilst making sense to screen readers, and other non-graphical devices, that might render the links out of context.
Ambiguous Link Phrases
Checkpoint 13.1 of WCAG 1.0, a priority 2 checkpoint, requires that authors clearly identify the target of each link.
Link text should be meaningful enough to make sense when read out of context either on its own or as part of a sequence of links. Link text should also be terse. For example, in HTML, write “Information about version 4.3” instead of “click here”. In addition to clear link text, content developers may further clarify the target of a link with an informative link title (e.g., in HTML, the
titleattribute).
The purpose of this checkpoint is to ensure that the visitor clearly understands the purpose and destination of each link in a document. This is particularly useful to screen reader users that may read link phrases out of context. Visually, ambiguous link phrases, such as, “click here”, “Read more”, and so on, might make sense when rendered visually in a graphical browser. However, the same ambiguous link phrases don’t make any sense whatsoever when read out of context. For example, JAWS has an option to display a list of links on the page with Insert + F7. Along with the JAWS keystroke to list all headings on a page (Insert + F6), gathering a list of links is a popular way for JAWS users to orientate themselves and quickly discover what they’re looking for in a document.
Although checkpoint 13.1 specifically mentions using the title attribute, the title attribute has very poor accessibility support with current user agents. By default, it isn’t announced automatically by most screen readers, and has poor keyboard support from major browsers. It is possible to access the content of the title in some major browsers, but the discoverability isn’t obvious. Fortunately, Cascading Style Sheets (CSS) offer a far better method to help developers provide context for non-visual user agents.
Some people argue that the content of a document isn’t intended to be read out of context, and they do have a point. However, ambiguous link phrases can be difficult to understand by all users, including screen reader users, even when they are read in context. As ambiguous link phrases can be difficult to comprehend by everyone, and given the fact that some screen readers offer their users the ability to extract links from a document to determine what links they have available, best practice is to ensure that all link phrases make sense when read out of context.
The following image illustrates what a JAWS user might be faced with from ambiguous link phrases in a typical blog:
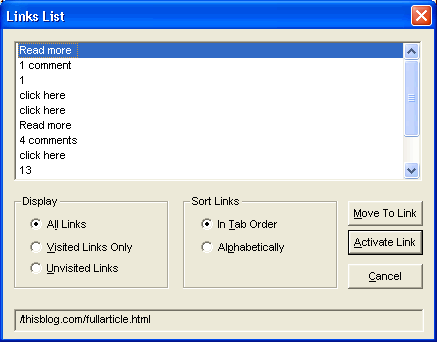
The link phrases in this example are meaningless, and there is no way that a typical screen reader user could reliably make sense of these link phrases, even though they might make perfect sense when rendered visually. The link phrases in this example might seem contrived, but they are taken from a popular website that advocates web standards, and quite typical of most blogs.
Uniform Design Patterns
Sometimes, a design may require a uniform pattern, such as repetitive “Read More” link phrases, being visually rendered in the document. This is perfectly acceptable, but doesn’t mean that link phrases shouldn’t make sense when read out of context.
For many years, developers have been using techniques to position content outside the visual viewport. The technique involves absolutely positioning the content outside of the viewport using CSS, so that those using graphical user agents that support CSS see the visual design as it was intended, and those using non-visual user agents receive the content including the parts that should be hidden visually. The following example demonstrates a variation on the technique with a class that is applied to a span element that is included in the content to provide context for non-visual user agents. The content of the span is rendered invisible in graphical browsers that support CSS, but is available for all other user agents.
A CSS class to provide context
span.context
{
position: absolute !important;
clip: rect(1px 1px 1px 1px); /* IE6, IE7 */
clip: rect(1px, 1px, 1px, 1px);
padding:0 !important;
border:0 !important;
height: 1px !important;
width: 1px !important;
overflow: hidden;
}Markup demonstrating the use of the context class
The following markup demonstrates how the context class might be used to provide context with a span element within a link phrase, without effecting how it is rendered visually in a graphical browser.
<a href="dest.html" href="dest.html">Read more
<span class="context"> about the origins of lemons</span></a>
This example would result in graphical browsers with CSS support displaying a link phrase of, “Read more”, whilst providing a link phrase of, “Read more about the origins of lemons”, which makes perfect sense when read out of context for all other user agents. The following image shows what is presented to a JAWS user using the above example:
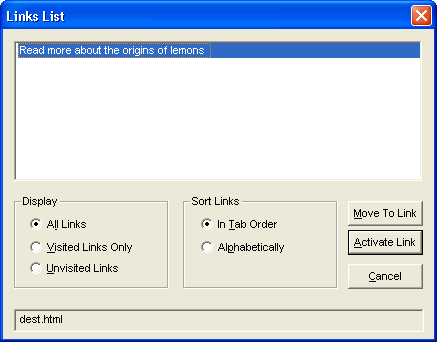
General Context
This technique isn’t just limited to providing context for link phrases. It can also be used to provide context for any element that, for whatever reason, is not intended to be rendered visually. For example, a design might not include headings, but headings are essential for screen users to understand the structure of a document. The context class can be applied to hidden heading elements, but the selector would have to be renamed from span.context to either *.context or just plain .context so that the class may be used by any element.
Structure isn’t just useful to screen reader users, but can also be essential for other users. For example, heading text can be helpful for people with cognitive impairments to understand the structure of a document. In these cases, hiding context should be the last option.
Comments
Maybe not forget about the importance of punctuation? A “period” will go a long way to avoid the ‘appearance’ of a run-on sentence. The same technique referenced of
.should be used for a header [and links] when punctuation within a header, for example, [or even table based content] is not intended as a design element.Not all users can afford the cost of a JAWS or Window-Eyes application. Some must rely upon simple HTML to speech rendering applications. The use of punctuation for these small apps is critical. One very good rule of thumb is always the use of good grammar and its structure. CSS can be used to truncate good grammar for visual design considerations.
This is a really interesting solution.
Gez, I’m wondering what you think about positioning the Context phrase before the link text?
So in the above example, it might read something like: ‘Origin of lemons. read more’. Even though it doesn’t read as well grammatically, it might be more usable…?
I’ve noticed in testing that users are so used to the meaninglessness of the ‘Read More’ link that they skip it before the screen reader finishes reading it out. As this is such an ingrained habit I imagine it would take a great deal of trust on the part of the user to hear each one out, in the hope that they were marked up as you suggest.
I do like this though and I can see it would be particularly useful in online papers etc.
Hi Lisa,
My instinct is that it would be better to front-load important information. “Read more …” is the most important information in context, and makes certain the user understands the purpose of the link. It’s a good point though, and I think it would be worth running tests with the text phrased correctly and the context front-loaded to determine which version people find more intuitive and usable.
Those of us who argue that HTML documents are structured in a tree and are, by definition, interpreted in sequence don’t merely have “a point†that reading out of context is not our problem, we have an airtight case.
If your toy has a function to disassemble and remix a structured document, don’t be surprised when the document ceases to make sense. And don’t expect developers to lift a finger to help you.
A link cannot simultaneously make sense in context and out of context. QED.
To Gez Lemon: IMO ‘Reading more’ is implicit in the presentation of the link so it’s not the most important information for frontloading. Additionally, it’s not the best text for search coverage and page ranking.
To all: I think it’s a good idea to strive for consistency in user experience for all users. A person looking at the screen must infer some of the information about the link from the text surrounding it while the person using the screen reader is presented with all the information.
Joe is quite right. HTML documents are structured and in writing, context is king.
Shifting context presents potentially unforeseen consequences.
Practically, however, I would have to say there is a strong case for the opposition.
“A link cannot simultaneously make sense in context and out of context.”
Interesting. The WCAG 1.O position requires that authors clearly identify the target of each link.
“Read more…” repeated throughout a page does not seem to meet this.
Some would argue that not only CAN links simultaneously make sense in context and out of context but that they MUST.
Visual users do not read in a linear fashion, especially on the web. Most people scan a page in a predictable fashion.
We glance around and see what catches our attention. Of course, if we are reading a technical specification or policy/legislation, that is a different story. Very few of us write this type of document, though.
Non-visual users have a significant problem that is only solved by exposing what is, hopefully, relevant information out of context. Forcing someone to read every word of a page to gain a contextual reference to every “Read more…” on a page is just an insane idea, when it is so simple to make it easier.
The above solution seems to be a balance between the layout of a page to satisfy an aesthetic concept and meeting a technical requirement.
The reference to a screen reader as a toy is just inflammatory and deserves nothing but derision.
I wonder what folks have to say about the new TEITAC technical provision that involves link text but renamed Link Purpose and harmonized with the WCAG 2.0 provision. The new proposed provision is as follows:
3-N – Link Purpose
On Web pages, it must be possible to determine the purpose of each link from the link text or the link text together with its programmatically determined link context.
* Note: In order to achieve this provision, links encoded in data operated on by the software would need to be associated with link text that the software can obtain as readily as it can obtain the link itself.
Rationale: Unlike the restrictive requirement in WCAG 1.0 which requires unique link text for each link within the page, this provision is more flexible. There are cases where it is actually more usable to have identical link text on several links such as on a page that lists document titles and provides links to versions of the document in different formats. This provision allows links within a page to have the same link text as long as the purpose of the link can be determined from the link text and its context, such as the table row or column header, list item, sentence, etc. Harmonization with WCAG 2.0.
Regards,
Mike
It seems sensible to allow context to be provided by the link phrase along with its programmatically determineable context, providing the programmatically determineable context is as readily obtainable as the link itself (as the note requires). It makes sense in cases where the link is in a table cell, and context can readily be obtained from a cell’s table header. It wouldn’t be possible to programmatically determine the context from a new sentence alone, unless context is provided by some other means that is as readily available as the table cell example.
It’s also worth noting that the proposed provision won’t help when links are repurposed with features such as “Links List”, provided by JAWS. JAWS could automatically provide the programmatically determinable context, but that then introduces problems with verbosity, as it would add verbiage even when the link makes sense out of context.
Agree with Gez – provision of contextual links is an easy win. We did this on our recent London Eye build with the “Book Now” links as seen in the home page. The context of the link is prepended programmatically and takes its value from the sectional heading. The links make perfect semantic sense and still have the brief visual context that designers like. The “Book Now” links are maintained automatically via the CMS so user error is kept to a minimum. Nice and simple.
In a few years as content/data becomes better labeled, structured and organized, users may have or should have the ability to reorganize a document to suite their particular requirements as is currently done with style and design. A user will be able to create an entirely separate and distinct document from a multitude of documents. That includes links. Couldn’t link relationships that are dependent upon surrounding context, table headers, whatever be identified by
rel="context"? Would such a relationship preclude user agents from grouping links out of context?Thank you very much.
I’m concerned about the audio verbosity of this technique. Sighted users get concise link text and screen reader users get the unnecessarily verbose text when navigating a page normally.
Using a definition list programmatically associates a
link with a
and thus gives it context. Unfortunately it still doesn’t currently help when generating a link list in a screen reader.
I think the way in which link lists are generated is at fault. Screen readers should allow at least some way of providing context, if only to end this debate 😉
I know that screen readers don’t generally read the titles on images and links (I think they should, but they don’t) – but could we use CSS to force them to?
If I include an aural.css, with a declaration of
a:after {content: ” (” attr(title) “) “; }
in the same way that I include the href in a print stylesheet, would this force the screen reader to enunciate the title … or would they just ignore it?